
最近一两年间,研究网络流量分析的各种流派,都殊途同归到“全流量”这个方向。你也全流量我也全流量,但究竟什么是全流量,大家不是语焉不详就是讳莫如深。更有甚者,拿开源IDS引擎来直接充当全流量,就像“人工智能”一样,兀自念了一个咒语,就能鸡犬升天。让人不能不感慨,一个IDS的时代结束了,这个时代的人还活着——这是一件很残酷、却很常见的事。
流量,顾名思义,即流淌于网络中的各种数据。全,则是全部的意思。放在一起,望文生义来说就是网络中全部的数据。用小学生的视角去看,与“全”对应的就是“部分”。使用过众多流量分析工具的各位都知晓,大部分工具输入的就是全部网络流量,那这个被大家集体鄙视的“部分”又从何而来?

PART1 全从何来
-
滞后性:真正的现象性需求,总是在事件发生后的一段时间出现,不管是网络入侵还是质量波动,很少在第一时刻被最终用户体会到,但是用户对源头的追溯往往却是不遗余力的。
-
模糊性:网络使用者,对现象的描述都是似是而非的,通常都是“好像中毒了”、“慢”、“卡”、“电脑不正常”等,澄清现状的过程本身就需要用细致的数据与其做交互,落实诸如:时间、应用、具体状态等。
-
离散性:由于滞后和模糊,在澄清需求和分析定位过程中,往往使用离散(告警)或切片(流量波动图)来驱动整个过程,虽然数字世界天生是一个离散的世界,但是对使用者来说他需要的是一个近似连续的实体,不能丢弃细节,就像没有人想在电视屏幕上看到大片的像素点。
PART2、全流量何以可能
-
时间维度






PART3、三个境界
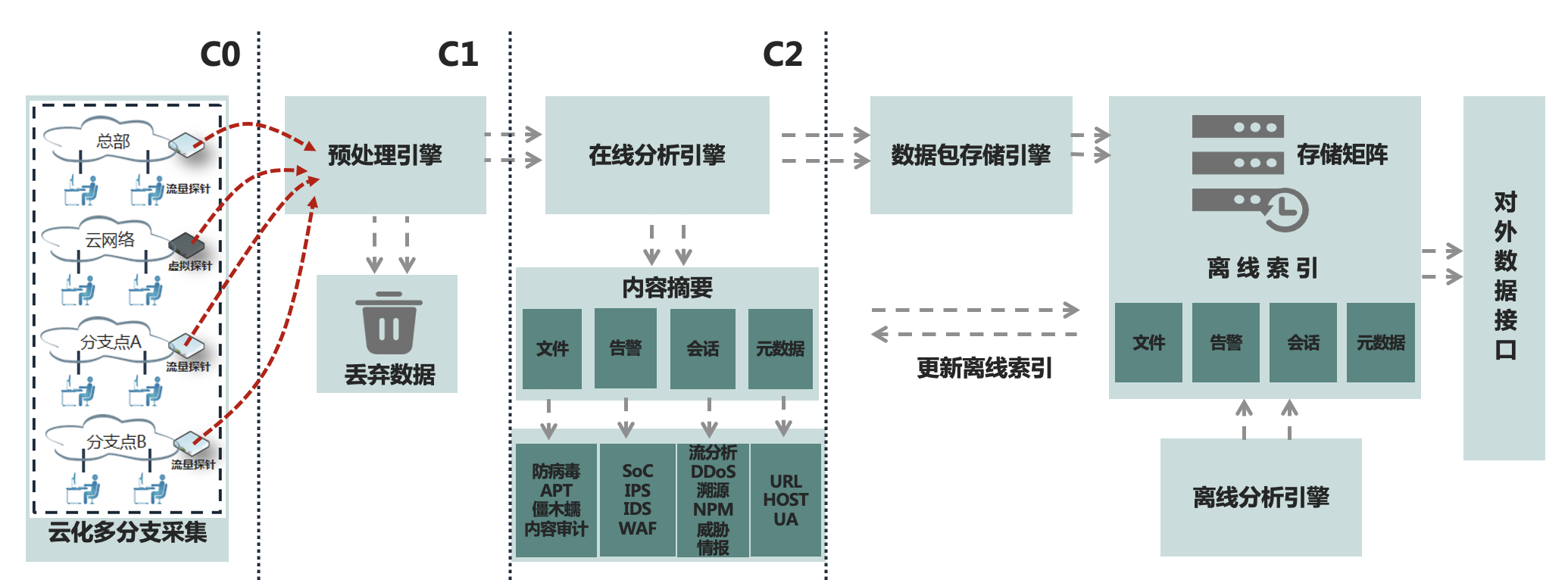
-
云化多分支采集
-
预处理引擎
-
在线分析引擎
-
数据包存储引擎
-
离线分析引擎
PART4、未来到哪里去
4.1软件定义的云化多分支采集
4.2跨越到应用层的流量预处理
4.3在线元数据“全”分析
4.4持续优化的包存储引擎
-
时序存储减少硬盘存储碎片
-
使用内存进行数据压缩
-
元数据、原始数据包分级存储
-
建立广泛的索引
-
存储的弹性化部署
4.5 离线智能化分析
-
在已知中寻找异常
-
在未知中排除正常
PART5、选择需要慧眼


数说安全
微信扫一扫


评论